




Every day, businesses generate massive amounts of unstructured data such as emails, reports, customer reviews, chat logs, and more. Buried within this chaos are insights that could drive smarter decisions, but extracting them? That’s the challenge.
Traditional data management systems were built for neatly organized spreadsheets and databases, not for handling the wild, free-flowing nature of unstructured content. As a result, businesses face inefficiencies, compliance risks, and missed opportunities, making it difficult to make data-driven decisions with confidence.
Enter Amazon Bedrock Data Automation, an innovative solution that leverages Generative AI to automate the transformation of multimodal data such as documents, images, audio, and videos into structured formats. With its advanced data extraction and transformation capabilities, you can build powerful Generative AI applications and automate complex workflows with greater speed and accuracy.
In this blog, we’ll explore how Amazon Bedrock Data Automation streamlines data extraction, accelerates transformation, and enables the creation of intelligent applications that drive actionable insights.
The Complexities of Extracting Insights from Multimodal Content
Data is everywhere, but making sense of it? That’s a whole different story. Businesses today are drowning in a sea of information, yet most of it remains untapped. Why? Because extracting valuable insights from diverse and complex data sources isn’t as simple as running a quick search or applying a one-size-fits-all solution. Let’s break down the challenges that stand in the way.
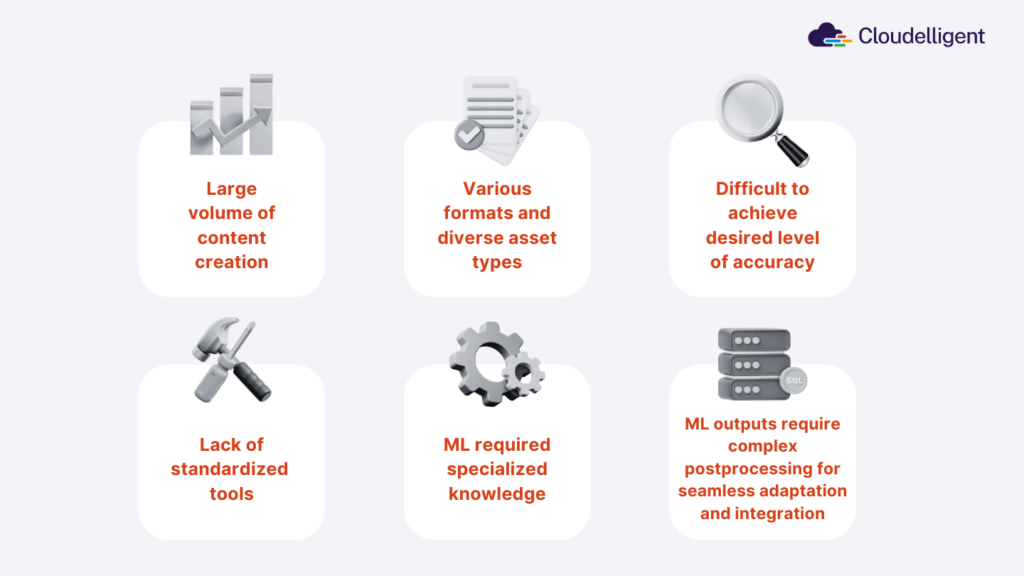
Figure 1: Challenges of extracting actionable insights from multimodal content
- Data Overload: Sifting through an endless stream of information manually is impossible, and traditional data systems simply can’t keep up.
- Diverse Formats: While structured data like spreadsheets is easy to process, businesses also deal with scanned contracts, voice memos, and even satellite images. Extracting insights from such varied formats remains a major challenge.
- Accuracy Challenges: Even with automation, errors persist. AI can misclassify data, misinterpret handwriting, or struggle with accents which can lead to costly mistakes in industries like finance, healthcare, and law.
- Lack of Standardization: When different departments store data in different ways, information gets trapped in silos. This lack of consistency slows collaboration, hinders decision-making, and creates inefficiencies.
- Machine Learning Complexity: ML can enhance data automation, but building, maintaining, and continuously updating models requires expertise and resources that many businesses don’t have.
- Integration Issues: The most advanced AI tools can still be ineffective if they don’t integrate seamlessly with existing workflows, causing disruptions and inefficiencies instead of streamlining operations.
Eliminating Data Bottlenecks with Amazon Bedrock Data Automation
Instead of struggling with these challenges, what if there was a way to seamlessly extract, organize, and analyze unstructured data, without the hassle of building complex AI models from scratch? That’s exactly what Amazon Bedrock Data Automation offers.
By leveraging pre-trained AI models, scalable cloud infrastructure, and seamless integration capabilities, Amazon Bedrock Data Automation simplifies the entire process. It can intelligently recognize diverse data formats, extract key insights with high accuracy, and integrate smoothly into existing business systems. As a result, law firms can streamline contract processing, banks can quickly analyze financial statements, and healthcare providers can efficiently manage patient records. Amazon Bedrock Data Automation is designed to help you transform unstructured data into a powerful asset that works for you, not against you.
How Can Data Automation Unlock Actionable Insights for Your Business?
Unlike traditional automation tools that struggle with varied data formats, Amazon Bedrock Data Automation is built to handle multimodal content at scale. It intelligently processes diverse data sources such as text, images, audio and video, transforming raw, scattered information into structured insights that drive smarter decision-making.
Let’s take a closer look at the features that make this possible.
- User-Friendly Interface: Amazon Bedrock offers an easy-to-use interface that allows you to define output schemas and set precise business rules with minimal effort.
- Advanced AI Orchestration: It integrates advanced, task-specific models alongside foundational models to ensure the generation of highly accurate and reliable outputs.
- Responsible AI Integration: Bedrock Data Automation includes built-in responsible AI tools, such as visual grounding, confidence scoring, and toxic content detection, ensuring ethical data processing and analysis.
- Seamless Amazon Bedrock Knowledge Base Integration: It connects directly with Amazon Bedrock’s Knowledge Base, which makes it easier to cross-reference information, validate outputs, and enhance decision-making.
- Scalability with a Single Interface API: Its single inference API enables efficient handling of production-scale workloads, ensuring smooth performance as your business scales.
Key Benefits of Leveraging Amazon Bedrock for Data Automation
Amazon Bedrock brings a transformative approach to handling unstructured data, making it easier for your businesses to extract, process, and utilize valuable information. By integrating AI-driven automation, it eliminates the inefficiencies of manual data handling and enhances accuracy, scalability, and operational efficiency. Below, we explore the key benefits of leveraging Amazon Bedrock for data automation.
- Faster Time-to-Value: You can use Amazon Bedrock Data Automation to accelerate the development of your Generative AI applications by automating the transformation of unstructured content such documents, videos, images, and audio.
- Customizable Outputs: Bedrock Data Automation can be easily customized to generate precise insights in the format your business requires. This helps ensure consistency and accuracy.
- Reduced Development Effort and Cost: It can also help you save time and resources with its unified API access and automated processing. This helps with faster production with fewer developers and lower upfront and operational costs.
How Amazon Bedrock Data Automation Works: Inputs and Outputs
Getting started with Amazon Bedrock Data Automation is easier than you think. It takes data in the form of documents, images, video, or audio, and helps to transform raw data into structured, actionable insights.
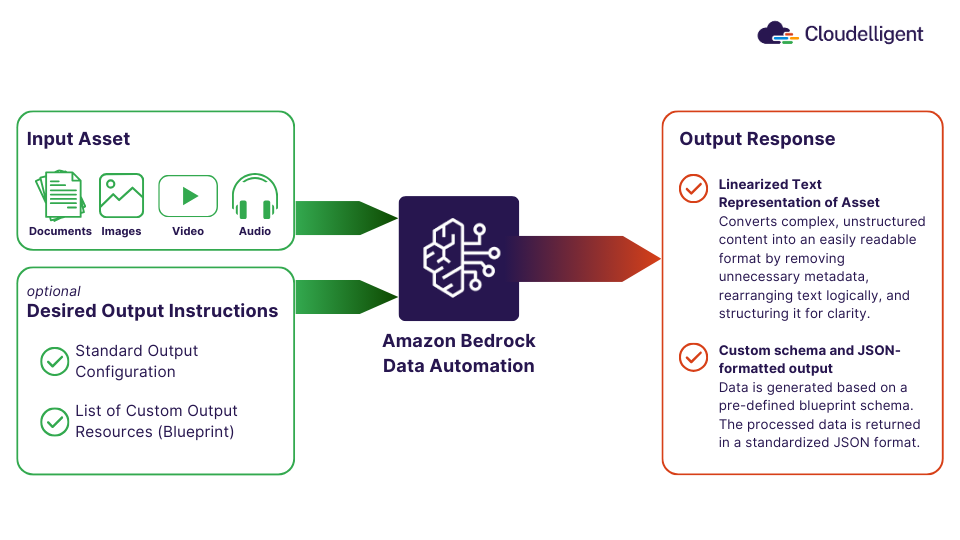
Figure 2: How Amazon Bedrock Data Automation processes the input asset and output instructions to generate an output response
Step 1: Input Asset
The process begins when you upload your input asset. This could be a document, image, video, or audio file. Bedrock Data Automation then analyzes the asset and processes it based on your chosen configuration.
Step 2: Choose Output Configuration (Optional)
Amazon Bedrock Data Automation allows you to customize the output based on your specific business needs. You can choose from:
- Standard Output: The default option, where it generates essential insights automatically. This includes text extraction, document summaries, video scene descriptions, or audio transcriptions.
- Custom Output: Available for documents and images only, this option lets you define specific data fields you want to extract using a blueprint. Blueprints ensure that the extracted information matches your business requirements.
Step 3: Output Response
Once the data is processed, Bedrock Data Automation delivers an output response in the form of:
- Linearized text representation of the asset: Converts complex, unstructured content into an easily readable format by removing unnecessary metadata, rearranging text logically, and structuring it for clarity.
- JSON-formatted structured output: The processed data is returned in a standardized JSON format, making it easy to integrate into other applications, databases, or AI models.
- Custom schema-based outputs (if using blueprints): For custom outputs, it generates results based on a predefined blueprint schema. This means that only the specific data fields requested are extracted, structured, and formatted in a way that aligns with business needs.
Types of Outputs That Can Be Returned
Not all data processing needs are the same, sometimes, you need a quick, AI-driven summary, while other times, you require precise, structured information. Amazon Bedrock Data Automation offers two distinct output types to cater to different business needs.
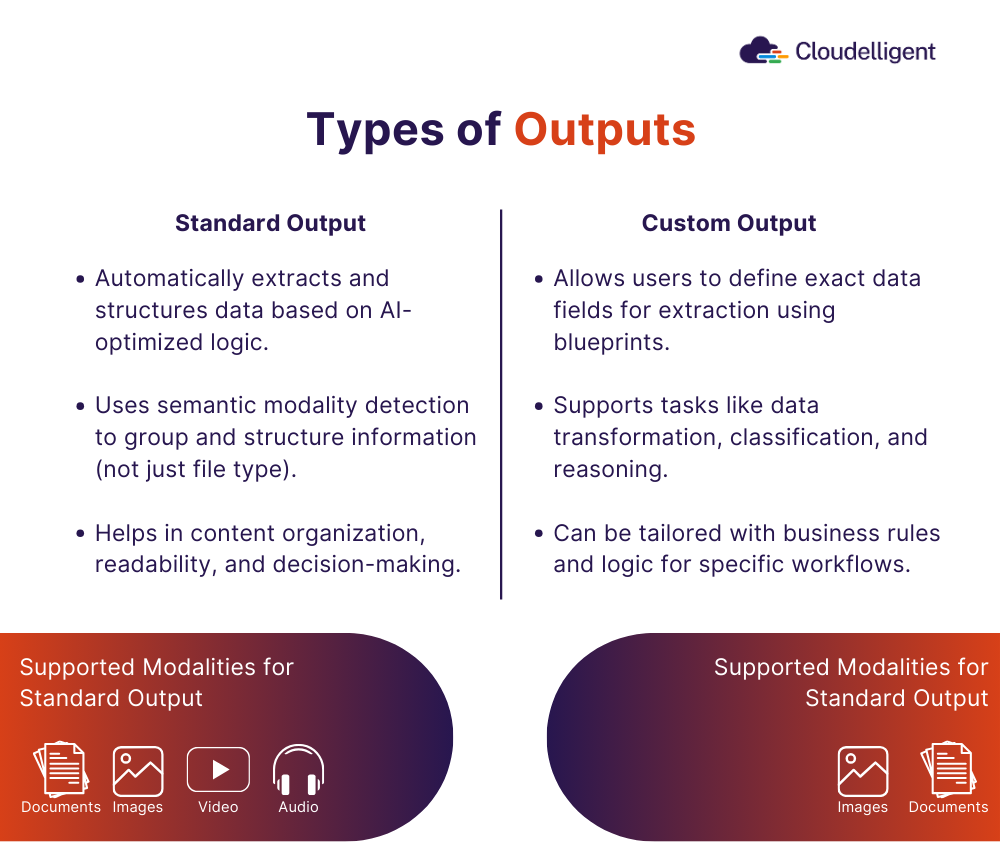
Figure 3: Types of output that Amazon Bedrock Data Automation can generate
Standard Output
- Automatically extracts and structures data based on AI-optimized logic.
- Uses semantic modality detection to group and structure information (not just file type).
- Helps in content organization, readability, and decision-making.
Custom Output
- Allows users to define exact data fields for extraction using blueprints.
- Supports tasks like data transformation, classification, and reasoning.
- Can be tailored with business rules and logic for specific workflows.
In short, it’s up to you to choose between the AI-optimized simplicity of standard output or the tailored precision of custom output. Amazon Bedrock Data Automation offers the flexibility to meet a wide range of your data processing needs.
Real-World Use Cases: Transforming Data into Business Value
Raw data alone doesn’t drive success, insights do. With Amazon Bedrock Data Automation, you can create robust Generative AI applications and automate processes such as media analysis and Intelligent Document Processing (IDP). Let’s dive into some real-world use cases that highlight the transformative power of Amazon Bedrock Data Automation.
Intelligent Document Processing
Amazon Bedrock Data Automation allows you to automate intelligent document processing (IDP) workflows at scale. It eliminates the need to manage complex tasks like classification, extraction, normalization, or validation, which simplifies the transformation of unstructured documents into structured, business-specific data. You can easily customize its output for smooth integration with your existing systems and workflows.
Media Analysis
Bedrock Data Automation brings valuable insights to unstructured video content. It helps generate scene summaries, detect inappropriate or explicit material, extract text from the video, and classify content based on brands or advertisements. These insights enable smarter video search, more effective ad placements, and enhanced brand safety and compliance.
Generative AI Assistants
Amazon Bedrock Data Automation also helps boost the performance of your retrieval-augmented generation (RAG) powered question-answering applications. By providing rich, modality-specific data extracted from your documents, images, videos, and audio, it enables more accurate and intelligent responses to user queries.
Speaking of Generative AI, have you checked out our blog? We’re breaking down 9 key strategies you need before building with Amazon Bedrock Agents. From performance to cost-efficiency, we’ve got the insights to help you create scalable, high-performing Gen AI applications.
Turn Data Chaos into Clarity with Cloudelligent
Amazon Bedrock Data Automation is a revolutionary solution for intelligent data processing, effortlessly transforming complex, unstructured data into structured, actionable insights.
At Cloudelligent, we specialize in harnessing AI-powered solutions such as Amazon Bedrock Data Automation to drive business transformation. With this service, we can help you create powerful Generative AI applications and automate critical use cases, such as content analysis and Intelligent Document Processing.
Ready to take the next step? Get a FREE AI Assessment today and see how we can help you take control of your data.



