Imagine logging into your business dashboard and seeing yet another complaint about your AI chatbot. Only this time, it gave a wildly inappropriate response to a simple customer query. Not only did it miss the mark, but it also offended someone. If you’re someone who relies on Generative AI to scale operations and enhance customer experience, this kind of misstep is simply unacceptable.
The reality is, unfiltered or unmoderated AI responses can severely damage customer trust, violate ethical standards, and lead to long-term reputational risks. In fact, a recent Pew Research Center study revealed that 55% of both AI experts and the general public are deeply concerned about bias in AI decision-making. This finding highlights the growing apprehension surrounding the reliability and fairness of AI-generated content.
The bottom line? Your Generative AI solutions need to be just as responsible as the rest of your business. It should reflect your values, communicate respectfully, and stay aligned with your brand voice, every time. That’s where tools such as Amazon Bedrock Guardrails can help. Designed to support the development of responsible Generative AI applications, Amazon Bedrock Guardrails offers features to guide AI behavior, apply brand-aligned rules, and maintain safe, consistent interactions across different use cases.
In this blog, we’ll explore how Amazon Bedrock Guardrails can help you build AI applications you can trust.
The Business Risks of Unrestricted Generative AI
When Generative AI applications are left unchecked, things can quickly spiral out of control. Without the right controls in place, your business might face serious consequences.
Let’s walk through a quick scenario: Imagine a chatbot responding to a potentially harmful user request, but with no guardrails in place.

Figure 1: Chatbot response before applying guardrails
Generative AI services on AWS are great at creating natural, human-like conversations. But as the scenario above shows, without proper safety measures, things can get messy really quickly.
Here are some of the most common risks that come with unmoderated AI applications:
- Offensive or Irrelevant Content: AI tools can sometimes produce toxic, inappropriate, or completely off-topic responses. This creates a poor user experience and can alienate customers.
- Factual Inaccuracies (Hallucinations): Generative AI is known to “hallucinate” or invent information. When that misinformation reaches your customers, it can lead to confusion and damage your credibility.
- Exposure of Sensitive or Private Data: AI models can unintentionally reveal confidential or personally identifiable information (PII) from their training data. This puts your business at risk of data leaks or privacy violations.
- Inconsistent Responses Across Different Models or Use Cases: Without unified guidelines, AI behavior can vary from one model to another, leading to unpredictable interactions that confuse users and reduce trust in your brand.
- Bias in Language and Responses: Bias in training data can lead to biased AI outputs. This can reflect poorly on your brand and raise ethical and legal concerns.
Each of these issues not only weakens customer trust but can also disrupt operations and raise compliance flags. To build AI applications that are safe and aligned with your business goals, you need to have clear guardrails in place from the start.
Another serious threat to look out for is Prompt Injections, particularly if you’re working with Amazon Bedrock Agents. Make sure to check out our blog on 7 Best Practices for Securing Amazon Bedrock Agents from Indirect Prompt Injections to stay one step ahead of these emerging risks.
What Are Amazon Bedrock Guardrails and Why Do They Matter?
As Generative AI becomes more deeply embedded in your business workflows, keeping its output safe, respectful, and on-brand is essential.
Let’s revisit that earlier chatbot scenario, this time with the right safeguards in place.

Figure 2: Chatbot response after applying guardrails
The difference is clear. With the right controls guiding the AI chatbot’s behavior, the outcome is not only safer but more on-brand and user-friendly.
This is where Amazon Bedrock Guardrails shine. It offers a powerful set of safety and compliance tools that help monitor and manage how your Generative AI applications behave. These guardrails can automatically filter out harmful, irrelevant, or off-brand content, stopping it before it ever reaches your users.
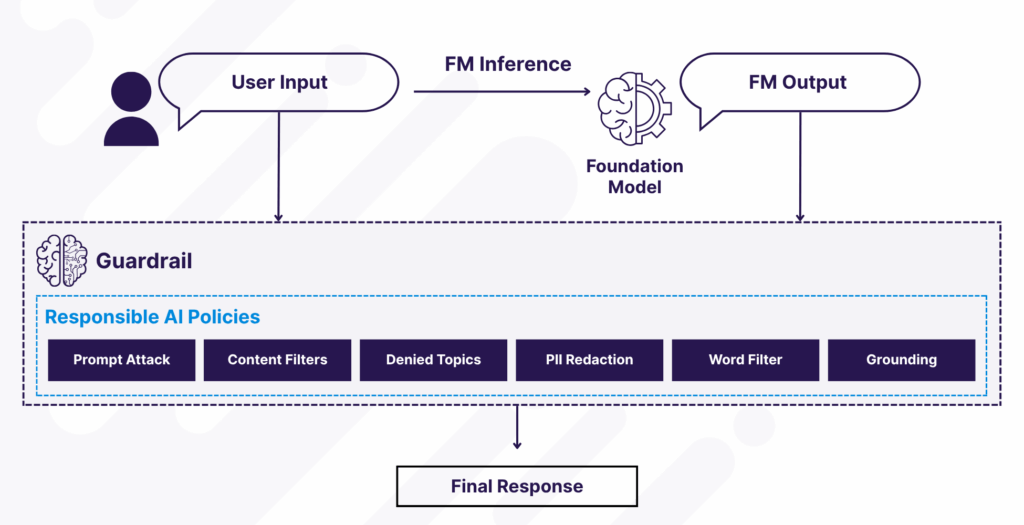
Figure 3: How Amazon Bedrock Guardrails Enforce Responsible AI Policies on User Inputs and Model Outputs
As shown above, adding guardrails doesn’t limit your AI chatbot’s creativity; it channels it. Think of guardrails as guidance systems: they help AI remain effective and innovative while staying aligned with your business values and user expectations.
Amazon Bedrock Guardrails are consistent, which means you can use the same set of controls with pre-trained foundation models, customized fine-tuned versions, and even models that run outside the Bedrock platform. This allows you to apply safety measures at scale without the complexity of managing separate systems.
As your use of Generative AI grows, so does the need to keep it responsible. Guardrails give you the control to scale without compromising safety or trust.
Your Generative AI applications are only as strong as their data security. Discover how to lock it down with practical tips from our latest blog: The Secret to Safe AI: Best Practices for Data Security in Generative AI Applications.
How Amazon Bedrock Guardrails Enable Responsible Generative AI Applications
Building responsible Generative AI means ensuring the output consistently reflects your standards for safety, accuracy, and brand integrity. Amazon Bedrock Guardrails provide a structured way to enforce these expectations by helping developers apply safeguards that keep AI behavior aligned with your business and ethical goals.
You can apply guardrails to all large language models (LLMs) in Amazon Bedrock, including fine-tuned models, and Agents for Amazon Bedrock.
Figure 4: Use Amazon Bedrock Guardrails to build safer AI applications
Speaking of which, Amazon Bedrock Agents are changing the game when it comes to automation. Discover how these agents are driving innovation while keeping security at the forefront in our blog: From Queries to Actions: How Amazon Bedrock Agents Are Revolutionizing Automation.
Here’s how Amazon Bedrock Guardrails help keep your AI applications in check:
1. Built-In Content Filters to Detect Profanity, Hate Speech, and Harmful Language
These filters detect and screen out harmful or unsafe text and images in both input prompts and AI responses. You can adjust the filter strength to match your risk tolerance and application needs.
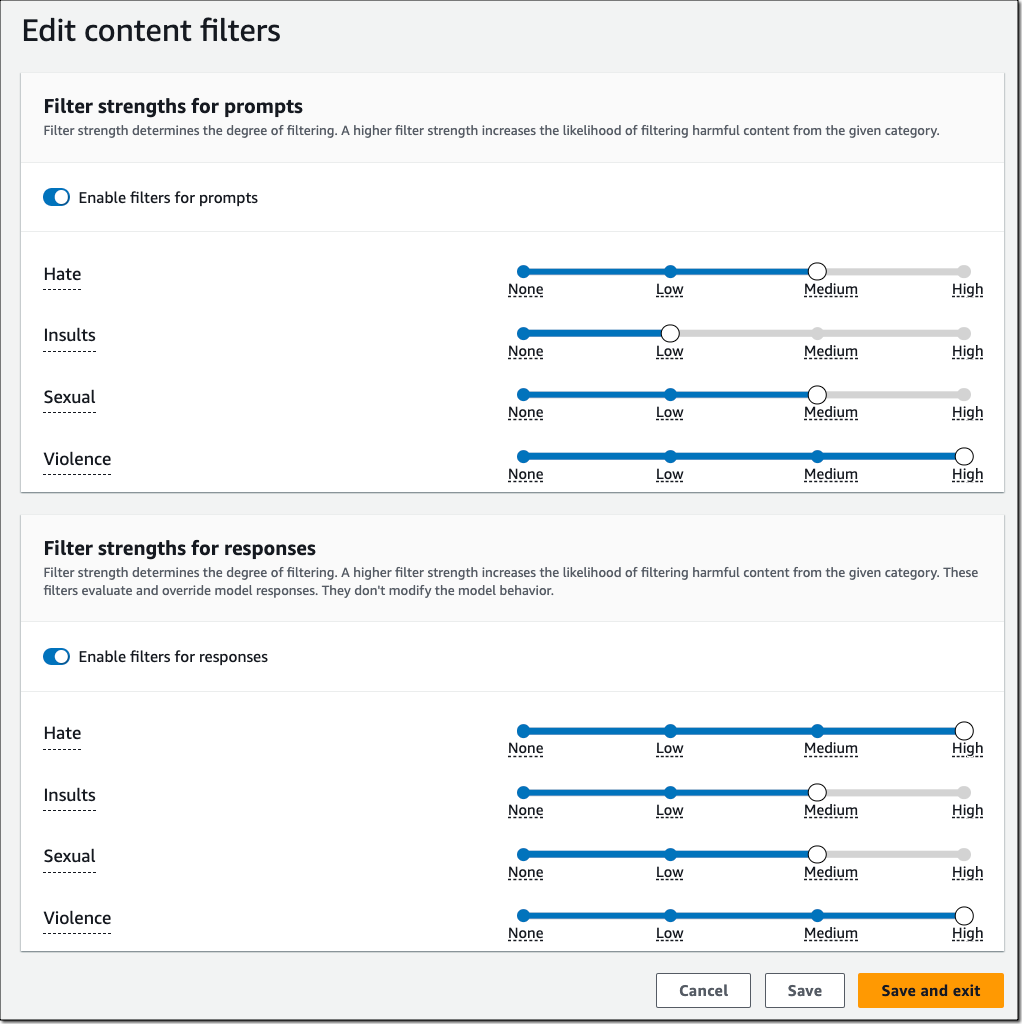
Figure 5: Filter harmful multimodal content based on responsible AI policies
2. Denied Topics Filter to Detect and Block Sensitive or Off-Limits Topics
If certain topics or language are off-limits in your business context, you can define and block them. This ensures your AI doesn’t stray into areas that could be damaging or irrelevant.
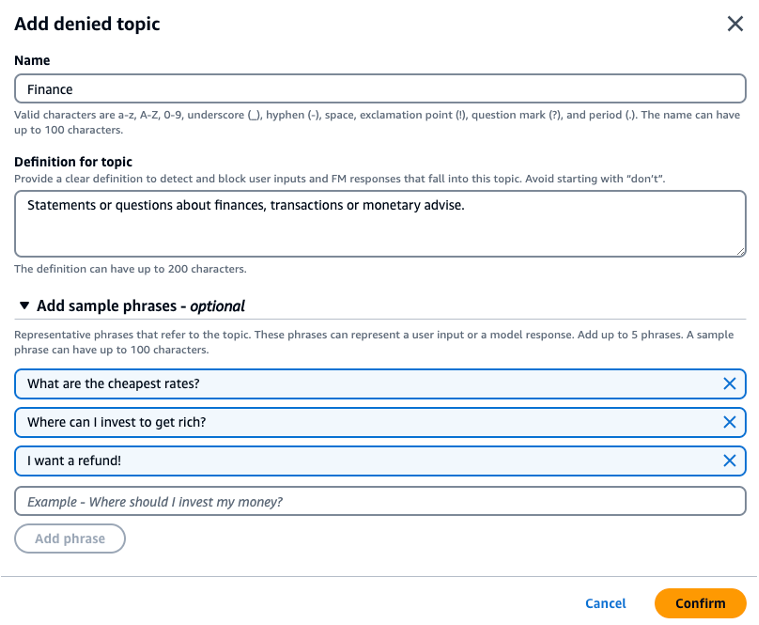
Figure 6: Restrict undesirable topics in Generative AI outputs
3. Sensitive Information Filters to Redact Personal Data in Prompts and Responses
Guardrails help identify and either block or mask sensitive personal information, such as social security numbers or birth dates. Detection is based on common formats and patterns used in standard identifiers.
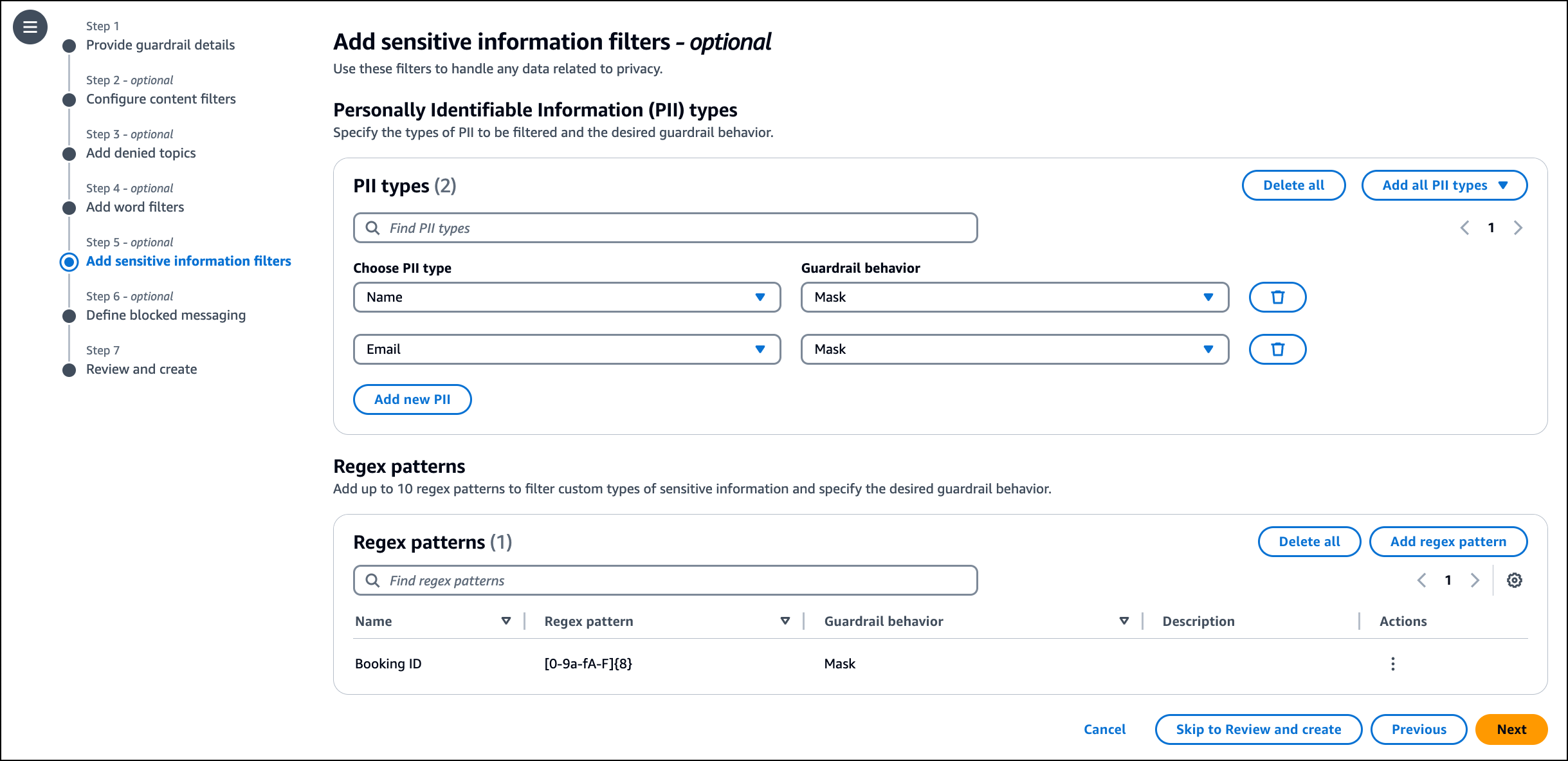
Figure 7: Automatically redact sensitive data like PII to ensure privacy
4. Contextual Grounding Checks to Validate Model Responses Against Trusted Sources
Amazon Bedrock Guardrails checks AI responses against trusted sources such as documents or chat history, to detect hallucinations. It ensures answers are both factually accurate and relevant to the user’s query.
Contextual grounding checks help ensure the model’s responses align with trusted reference material by evaluating two key factors:
- Grounding: Determines whether the model’s response is factually supported by the source content. Any information that is not present in the original source is considered ungrounded.
- Relevance: Assesses whether the model’s response directly addresses the user’s question. A response may be correct in isolation but still irrelevant if it strays from the query’s intent.
For example, if a document states, “Mount Everest is the tallest mountain in the world,” and the model replies, “K2 is located in Pakistan,” the response is ungrounded. If it says, “K2 is the second-tallest mountain,” it’s factually correct but irrelevant to the original query about the tallest mountain.

Figure 8: Identify hallucinations in responses using contextual grounding checks
Each response is also assigned confidence scores for grounding and relevance, which reflect how well it aligns with the source content and user query. You can set thresholds to automatically filter out responses that fall below acceptable scores. For instance, setting both thresholds to 0.7 ensures that any response scoring lower will be flagged as potentially hallucinated and blocked. This helps reduce the risk of ungrounded or off-topic content appearing in your Generative AI application.
5. Automated Reasoning Checks to Verify Logical Consistency and Factual Accuracy
These checks are designed to help ensure that AI-generated responses aren’t just plausible on the surface but are actually correct and aligned with your internal standards. They rely on logic-based, mathematical reasoning to validate whether a model’s output truly matches your organization’s defined rules, policies, and documented facts.
Automated reasoning checks primarily focus on two key aspects:
- Logical Validity: Is the model’s response logically consistent with your policies and rules? If it contradicts them, it gets flagged.
- Factual Consistency: Do the values or statements in the response match what is explicitly stated in your documents?
For example, if your HR policy clearly states, “Employees must submit leave requests two weeks in advance,” and the AI responds with, “You can take leave with 24 hours’ notice,” that response would be marked as invalid, as it directly violates the established rule.
To avoid such inconsistencies, you can set up reasoning policies within your Amazon Bedrock console in the following way:
- Upload internal documents (such as HR policies or SOPs) to automatically generate rules
- Define the policy intent and filter out irrelevant content
- Refine the logic using a visual editor with human-readable formats
- Test and enhance the policies using sample Q&A
- Link these policies to guardrails for real-time validation during AI interactions.

Figure 9: Prevent factual errors with Automated Reasoning and grounding for accuracy
By integrating these steps into your setup, you create a robust framework that filters content and actively reasons through it. Unlike basic content filters, Automated Reasoning checks allow you to mathematically verify that a model’s output is grounded in truth. This level of assurance is particularly valuable in regulated industries, enterprise knowledge systems, or customer-facing chatbots, where inaccuracies can result in compliance violations, financial risks, or loss of trust.
Once implemented, these checks classify AI responses as one of the following:
- Valid: Fully aligned with the defined logic
- Invalid: Violates one or more established rules
- Mixed: Partially correct, but with some inconsistencies
This classification isn’t just for reporting purposes, rather it plays an active role in improving response quality. The feedback from each classification loops directly back into the prompt, enabling the model to automatically regenerate more accurate and compliant answers.
Moreover, as your internal policies change over time, you can update the rules using natural language, and Amazon Bedrock takes care of converting them into the necessary logical structures behind the scenes, ensuring your AI remains aligned with your latest standards.
By layering these controls into your Generative AI workflow, you can better manage risk, improve reliability, and maintain user trust, without sacrificing innovation.
Real-World Impact: Guardrails for Responsible AI Across Industries
Amazon Bedrock Guardrails provide customizable safeguards designed to meet the unique demands of Generative AI applications across various industries and their responsible AI policies. You can create multiple guardrails for different use cases and apply them consistently across various foundation models. This approach helps ensure a uniform user experience while standardizing safety and privacy measures across all your AI-powered solutions. Amazon Bedrock Guardrails seamlessly manage both user inputs and AI-generated responses through natural language controls.
To truly grasp the power of Amazon Bedrock Guardrails, let’s look at how they’re being applied in key industries to protect Generative AI applications:
Customer Service in Retail and eCommerce
In chatbot applications, guardrails can help filter harmful or abusive language from user inputs and ensure the model doesn’t respond with toxic, biased, or irrelevant content. This protects customer interactions and supports brand integrity in high-volume, public-facing environments.
Financial Services and Banking
Banks and investment firms can configure guardrails to block prompts or responses related to offering investment advice or financial predictions. This helps them to stay compliant with regulatory standards and avoid liability for unverified claims.
Healthcare Call Centers
In call centers handling sensitive patient information, AI applications summarizing conversations between patients and agents can use guardrails to automatically redact personally identifiable information (PII), such as names, addresses, or birthdates. This helps maintain HIPAA compliance and safeguards patient privacy.
Education and Edtech
In AI-powered learning tools designed for young students, Amazon Bedrock guardrails can help filter out inappropriate content and automatically redact any personal details submitted through prompts. This ensures the AI responses are age-appropriate, curriculum-aligned, and respectful of student privacy. This helps foster a safe and engaging digital classroom environment.
Fundraising Campaigns in Nonprofit Organizations
In charity organizations running fundraising campaigns, AI applications generating donation emails can use Amazon Bedrock Guardrails to ensure messaging is clear, accurate, and free from misleading claims. Guardrails also automatically redact sensitive donor information, such as payment details and contact data, to help protect privacy and maintain donor trust.
Turn AI Complaints into AI Compliments with Cloudelligent
Generative AI can be incredibly powerful, but sometimes it can lead to unpredictable or unsafe outcomes. Rather than abandoning your AI initiatives due to these challenges, you can take control by establishing clear boundaries with Amazon Bedrock Guardrails. These safeguards help you manage risks, reinforce compliance, and ensure consistent, high-quality user experiences.
At Cloudelligent, we partner with you to design, implement, and fine-tune Amazon Bedrock Guardrails tailored to your unique business requirements. From configuring content filters and custom policies to aligning model behavior with brand values, we help make your AI applications safer, smarter, and more trustworthy.
Ready to make your Generative AI applications more responsible? Request a FREE AI/ML Assessment today and find out how we can help you improve safety, enhance user experience, and fully harness the power of Amazon Bedrock Guardrails.