




Data is the lifeblood of modern innovation, and AI is the brain that brings it to life. As the race to dominate the AI frontier intensifies, companies are investing heavily in AI technologies. According to a report by McKinsey, 60% of companies have integrated AI into their operations in the past year alone. This staggering growth is expected to continue with the market racing past 826 billion U.S. dollars in 2030.
Generative AI success goes beyond prompt engineering and content distribution. It requires integration within a comprehensive data science strategy built on strong data architecture foundations. Yet, many organizations find their traditional data platforms ill-equipped for AI initiatives, plagued by issues of scalability, flexibility, and real-time processing. To truly succeed with AI, your business needs a data infrastructure that is as adaptive and forward-thinking as the technology itself. Moreover, we believe both data architecture and data engineering should be cloud-native to optimize performance and scalability for AI innovation.
This blog delves into the strategic design principles and best practices for building a future-ready data architecture on AWS, ensuring your AI initiatives are not just cutting-edge but also sustainable and scalable.
The Role of Data Architecture in Generative AI
Traditional data platforms often fall short of meeting the demands of modern AI workloads. These challenges include:
- Data Silos: Isolated data sources hinder comprehensive analysis AI model training, as models require a comprehensive view of information.
- Scalability: Legacy architectures may struggle to handle the massive datasets and computational demands of AI workloads.
- Security: Ensuring data privacy and protection is challenging with outdated architectures.
- Performance: AI models require fast access to data for efficient training and inference. Latency can significantly impact model performance.
To overcome these limitations, businesses must transition to modern, cloud-based data pipelines capable of supporting AI’s evolving needs.
A well-designed cloud data platform is the backbone of successful AI initiatives. It ensures that data is accessible, scalable, and secure which enables Generative AI applications to generate meaningful insights and create transformative user experiences. By seamlessly storing, processing, and managing vast amounts of structured and unstructured data, a robust architecture accelerates AI model training and deployment. Additionally, it enhances real-time decision-making and powers personalized recommendations.
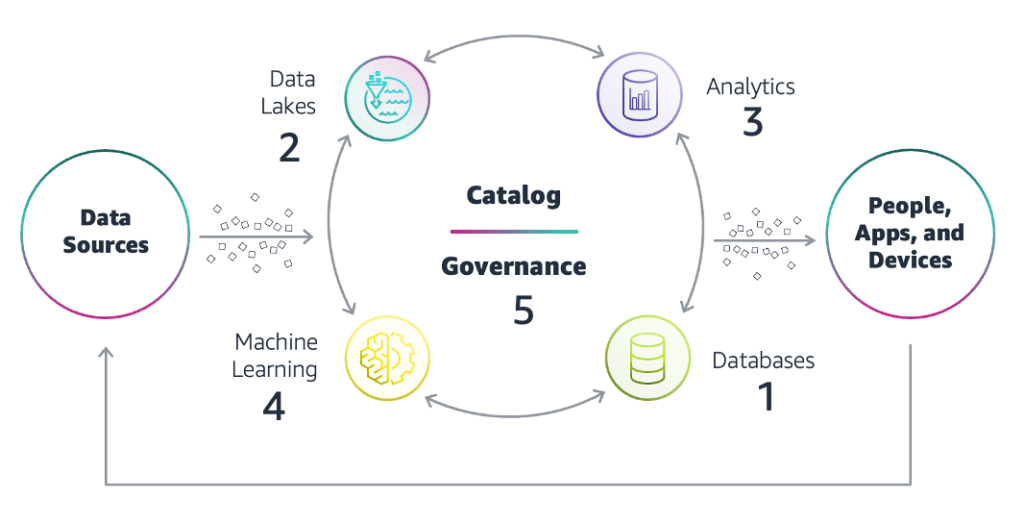
Figure 1: High-level design for a modern data architecture on AWS
Consider a scenario where a healthcare provider attempts to develop a Generative AI model for predicting patient outcomes. Due to data silos between different departments, the AI team faces difficulties in accessing comprehensive patient records, limiting the model’s accuracy and effectiveness. By transitioning to a modern data architecture on AWS, the provider can establish a centralized data lake, integrate data from various sources, and ensure data quality, leading to a more accurate and valuable AI model.
With a future-ready data architecture in place, your business can unlock a wide range of AI-driven opportunities such as:
- Enhanced Decision-Making: Generative AI models can provide valuable insights into complex data sets which can enable you to make more informed decisions.
- Predictive Analytics: By analyzing historical data, generative AI can help your business predict future trends and anticipate customer needs.
- Personalized User Experiences: Generative AI can be used to create personalized experiences for your customers, such as recommending products or services based on their preferences.
Building Blocks of an AI-Driven Data Architecture
To establish a robust and scalable cloud data platform, it is essential to carefully consider the core components that will support the ingestion, storage, processing, and analysis of your data. On AWS, this ecosystem is powered by a range of services that ensure data is handled at every stage of its lifecycle with speed, scalability, and flexibility. Below are the core building blocks.
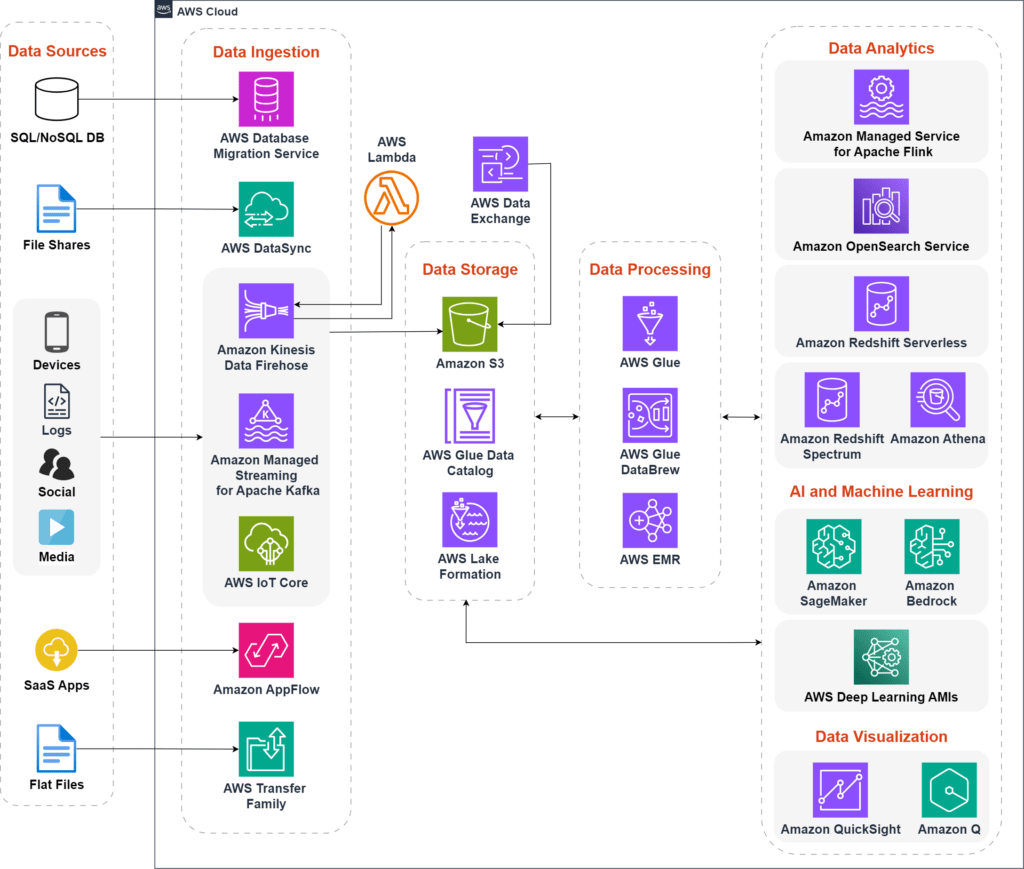
Figure 2: A modern data platform leveraging a range of Amazon Web Services to fuel AI innovation
Data Ingestion
The first step in building an AI-driven data platform involves efficiently ingesting data into the AWS environment. Data is collected from a multitude of sources across your organization, including SaaS applications, edge devices, logs, streaming media, flat files, and social networks. The diversity of data sources necessitates a robust and flexible ingestion framework. AWS offers a suite of services tailored to handle various types of data sources:
- AWS Database Migration Service (DMS): Ideal for migrating databases to AWS with minimal downtime.
- AWS DataSync: Automates and accelerates moving data between on-premises storage and AWS.
- Amazon Kinesis: Captures, processes, and analyzes real-time streaming data.
- Amazon Managed Streaming for Apache Kafka: Simplifies the setup, running, and scaling of Apache Kafka clusters for operating real-time data streaming applications.
- AWS IoT Core: Connects Internet of Things (IoT) sensors to the cloud and collects data from them.
- Amazon AppFlow: Facilitates data transfer between SaaS applications and AWS services.
- AWS Transfer Family: For transferring flat files (such as CSV, JSON, and XML files) between on-premises systems and AWS.
These services ensure seamless ingestion of both batch and real-time data into AWS. This foundational step paves the way for subsequent processing and analysis.
Data Storage and Management
Once data is ingested, it needs to be efficiently stored and managed. You can leverage a variety of scalable storage solutions designed to handle different types of data, whether structured, semi-structured, or unstructured:
- Amazon S3: Offers scalable object storage for a wide range of data types.
- Amazon EFS: Provides scalable file storage for use with AWS Cloud services and on-premises resources.
- Amazon FSx: Delivers fully managed file storage built on popular file systems.
- Amazon DynamoDB: A key-value and document database that delivers single-digit millisecond performance.
Data storage on AWS goes beyond simply holding data. It integrates seamlessly with management services such as AWS Lake Formation to create a centralized data lake. This lake is built on Amazon S3 and offers granular security and governance controls. AWS Lake Formation also ensures centralized governance, managing security, access control, and audit trails.
AWS Glue Data Catalog serves as the metadata repository for all the data. This makes it easy to locate and organize datasets within the data lake. Moreover, AWS Data Exchange helps integrate third-party datasets into the data lake, offering businesses access to external data sources that can enrich AI models.
Data Processing
Data processing is crucial for transforming raw data into valuable insights. You can take advantage of a rich set of tools to handle Extract, Transform, and Load (ETL) processes and big data workloads.
- AWS Glue: Automates ETL tasks, making it easy to clean, transform, and load data for analytics across multiple stores and into the data lake.
- AWS Glue DataBrew: Offers a visual data preparation tool for cataloging, transforming, enriching, moving, and replicating data across multiple data stores and the data lake.
- Amazon EMR: Provides a scalable platform for processing large datasets using open-source big data frameworks like Apache Hadoop and Apache Spark.
These tools enable the transformation, enrichment, and movement of data across multiple data stores and the data lake, ensuring that data is ready for analysis or training AI models.
Data Analytics and Visualization
AI models thrive on data, and the final step in the AI-driven data architecture is leveraging analytics tools to generate actionable insights. You can select from a range of AWS services for analyzing data at scale:
- Amazon Managed Service for Apache Flink: Transforms and analyzes streaming data in real-time.
- Amazon OpenSearch Service: Provides operational analytics, offering search and data visualization capabilities.
- Amazon Redshift Serverless: A cloud-based data warehouse that scales automatically based on your workload. With federated queries, you can query and analyze data across operational databases, data warehouses, and data lakes. You get insights from data in seconds without having to manage data warehouse infrastructure.
- Amazon Redshift Spectrum and Amazon Athena: For interactive querying, Amazon Athena allows users to run SQL queries on data in S3. Amazon Redshift Spectrum extends this capability to Redshift data warehouses. Both services enable fast data retrieval and analysis without complex ETL processes.
- Amazon QuickSight: For machine learning (ML)-powered business intelligence, providing interactive dashboards and visualizations.
- Amazon Q: Enables natural language querying and empowers you to generate insights using simple questions such as “What are my top-performing products?”
By combining these building blocks, AWS enables businesses to design a data architecture that’s fully optimized for AI innovation. Hence, ensuring scalability, flexibility, and real-time analytics for AI-driven decision-making.
For more insights on near-instantaneous data visualization on AWS, check out our blog post – How Generative BI on Amazon Q in QuickSight Drives Real-Time Insights.
Integrating AI and Machine Learning
Harnessing the true power of AI goes beyond mere algorithms. It demands a seamless integration of cutting-edge tools and a robust data infrastructure. You can select from a comprehensive suite of AI and ML services that can easily integrate with your cloud-native environment, enabling you to build, train, and deploy sophisticated AI models. Key services include:
- Amazon SageMaker: A fully managed platform for building, training, and deploying machine learning models at any scale.
- Amazon Bedrock: A fully managed service that makes foundational models accessible through an API, allowing developers to build generative AI applications.
- AWS Deep Learning AMIs: Preconfigured Amazon Machine Images (AMIs) optimized for deep learning frameworks like TensorFlow and PyTorch.
These services work in conjunction with your AWS data architecture components to streamline the entire AI/ML lifecycle. For instance, data can be ingested into an Amazon S3 data lake, processed using AWS Glue, and then prepared for model training using Amazon SageMaker. Trained models can be deployed to Amazon SageMaker endpoints for real-time inference or to batch processing environments using Amazon EMR.
AI/ML Workflow
A typical AI/ML workflow on AWS involves the following steps:
- Data Preparation: Ingest and prepare your data using AWS services like Amazon Kinesis Data Firehose, AWS Glue, and AWS Data Wrangler.
- Model Building and Training: Build and train your model using Amazon SageMaker, AWS Deep Learning AMIs, or Amazon Bedrock. Leverage tools like Amazon SageMaker Studio for a fully integrated development environment.
- Model Deployment: Deploy your trained model as a web service using Amazon SageMaker Hosting or Amazon Elastic Container Service (ECS).
- Model Monitoring and Management: Monitor your model’s performance in production using Amazon SageMaker Model Monitor and AWS CloudWatch.

Figure 3: Key stages of an Artificial Intelligence/Machine Learning workflow
Building and Training Models
When building and training AI models, you can follow these best practices:
- Data Preparation: Ensure your data is clean, consistent, and representative of the problem you’re trying to solve.
- Model Selection: Choose the appropriate model architecture based on your problem and data characteristics.
- Hyperparameter Tuning: Experiment with different hyperparameters to optimize your model’s performance.
Operationalizing AI
Once your AI model is deployed, it’s essential to monitor and manage its performance:
- Amazon SageMaker Model Monitor: Track your model’s performance over time and detect anomalies.
- AWS CloudWatch: Monitor metrics like latency, throughput, and error rates.
- Retraining: Regularly retrain your model to maintain its accuracy as data changes.
To illustrate how AWS services can be combined for a complete AI solution, consider a scenario where a financial services organization wants to develop a fraud detection model. The bank can use AWS DMS to migrate historical transaction data into an Amazon S3 data lake. It can process the data using AWS Glue, and train a fraud detection model using Amazon SageMaker. The trained model can then be deployed to Amazon SageMaker endpoints for real-time fraud detection, with Amazon CloudWatch monitoring the model’s performance and alerting on anomalies.
Best Practices for Implementing AI-Ready Data Architectures on AWS
To maximize the potential of Generative AI on AWS, follow these best practices for designing an AI-ready data architecture:
- Design for Modularity and Reusability: Utilize microservices and serverless architectures to create modular components that can easily scale and adapt to evolving AI needs. AWS Lambda and API Gateway are ideal for this approach.
- Automate Data Management: Implement automated workflows using AWS Step Functions and AWS CloudFormation to streamline data lifecycle management and ensure consistent governance and compliance.
- Optimize Data Quality: Regularly clean, validate, and enrich your data with tools like AWS Glue DataBrew to maintain high-quality datasets for reliable AI model outcomes.
- Enable Data Democratization: Make data accessible across your organization by using AWS Glue Data Catalog and empowering non-technical users with self-service analytics tools.
- Optimize Performance and Costs: Use auto-scaling, load balancing, and AWS Cost Explorer to ensure performance optimization while managing expenses efficiently.
Modernize Your AWS Data Architecture for Generative AI
At Cloudelligent, we specialize in delivering data architecture solutions to meet the unique needs of organizations across various sectors, including finance, healthcare, and manufacturing. Our expertise lies in developing and executing data acceleration strategies that enable businesses to leverage Generative AI use cases effectively. By focusing on the specific challenges and goals of each sector, we have successfully implemented AI-ready architectures that drive innovation and efficiency.
Thinking about evaluating your current data platform? Our experts are here to assist in optimizing your data strategies for Generative AI. Contact us today for a Free Data Acceleration Assessment and discover how we can help you design a future-ready data architecture on AWS.



